
Differentiated Data Recipes, Undifferentiated Compute
The applied AI recipe in 2026

Vertical AI is on track to continue to create massive value in a number of verticals. But essential questions endure about their long term value, current multiples, and more given the continued advances in foundation models.

While there are certainly some companies that have spent time training models, most of the optimizations have been at the prompt level or in the supporting system around LLMs.
This has made quite a bit of sense over the past few years.
Vertical AI companies were cognizant that they were going to get a performance upgrade without spending really any time on R&D/ML research. Every new model release was a guaranteed performance upgrade.
The foundation labs struck a peace dividend by depreciating their older models rapidly and releasing smaller, cost-optimized models.
So the net result was a race for industry adoption with most vertical AI companies paying less attention than probably is warranted to questions around the model layer or even research-oriented questions around how to create systems that maximized current AI capabilities (a lot of the context graph discussion is around this reality).
Simply put, there wasn’t a clear throughline between the model layer and the research questions being asked around data recipes, algorithms, RL environments, and the value they were looking to create in their vertical.
Very quickly, that’s all begun to change. I’ve spent the past two months talking to a wide-range of players across the compute, data, and RL environments landscape to understand the reasons why this is changing.
Don’t worry, some of these interviews are going to be published very soon. But I first wanted to talk through the factors themselves shaping the market:
Everyone is getting sophisticated around algorithms as the knowledge disseminates
ML techniques are continuing to proliferate. Before diving into the post-training layer around LLMs, it’s important to note that ML sophistication doesn’t necessarily just mean LLMs. Companies are increasingly building more traditional models as a core part of their infrastructure for whatever applied problem they’re tackling.
But as it applies to LLMs, training is no longer a trade secret only known in the labs. RL techniques and optimizations are now widespread, frameworks like verl and solutions like Tinker have delivered teams the ability to work on these without having to know a ton about the low level engineering. And of course, open source base models like the Qwen series are powerful out of the box and ripe for these recipes.
The barrier to entry on the research side has lowered with the net result that more companies are at least beginning to explore post-training techniques. So far this has been primarily seen amongst the coding players, but there are early indicators that across law, healthcare, finance, and more, the dissemination of algorithms is causing teams to experiment in ways they weren’t a year ago.
At minimum, applied AI companies are thinking about their task as fundamentally a mixture of algorithmic design.
Compute continues to commodify
While still expensive, the last year has seen the rise of inference hosting services like Baseten, spot markets for compute training develop, and even players beginning to formalize true commodity derivatives products for compute.
Whereas most teams 2 years ago would have had to procure a GPU cluster on their own, they can now interact with compute clusters in a similar manner to traditional cloud services. This naturally enables companies to experiment more + scale up in more capital efficient manners if their smaller model starts to become adopted.
This changes not only the unit economics of training but of model distribution. And since potentially higher model performance can be delivered for even lower COGs than using foundation models, this is becoming more and more attractive.
Data is the last undefined asset and where moats are accruing
I want to be careful here to define data in a particular way. What I am not suggesting here is that raw data itself is a particularly good moat. As everyone is well aware, interoperability has meant that structured + raw data is leaving and entering systems all the time. The storage of data is not really proprietary nor that valuable for applied AI companies. While someone will continue to own data storage (the systems of record), the data itself is not uniquely valuable to training.
What is valuable is what I’m going to call the data recipe - ie how do agents when looking at a problem or task provided work their way through a problem to an economically valuable result.
And this is where all the interesting dynamics in applied AI are headed. Perhaps it’s helpful to first consider how the labs are ascertaining this today:
Expert marketplaces
Expert marketplaces like Mercor, Turing, and others derive their data recipes from having experts in a domain create tasks and rubrics for training models on how to make proper decisions.
Here’s a toy example: A doctor hired through Mercor will create a fact pattern around a patient and then provide a grading rubric for how the model should assess the right decision to make in regards to the patient.
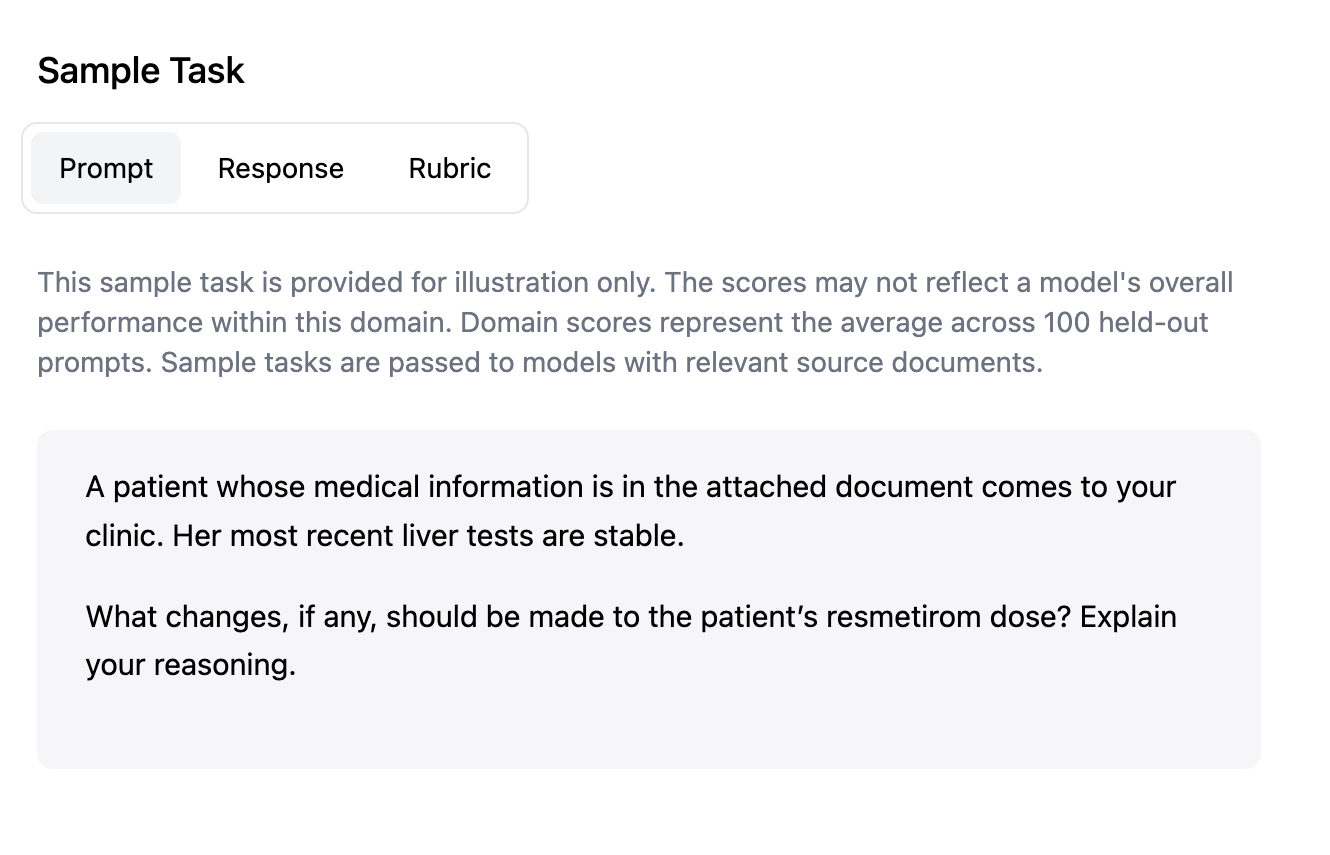
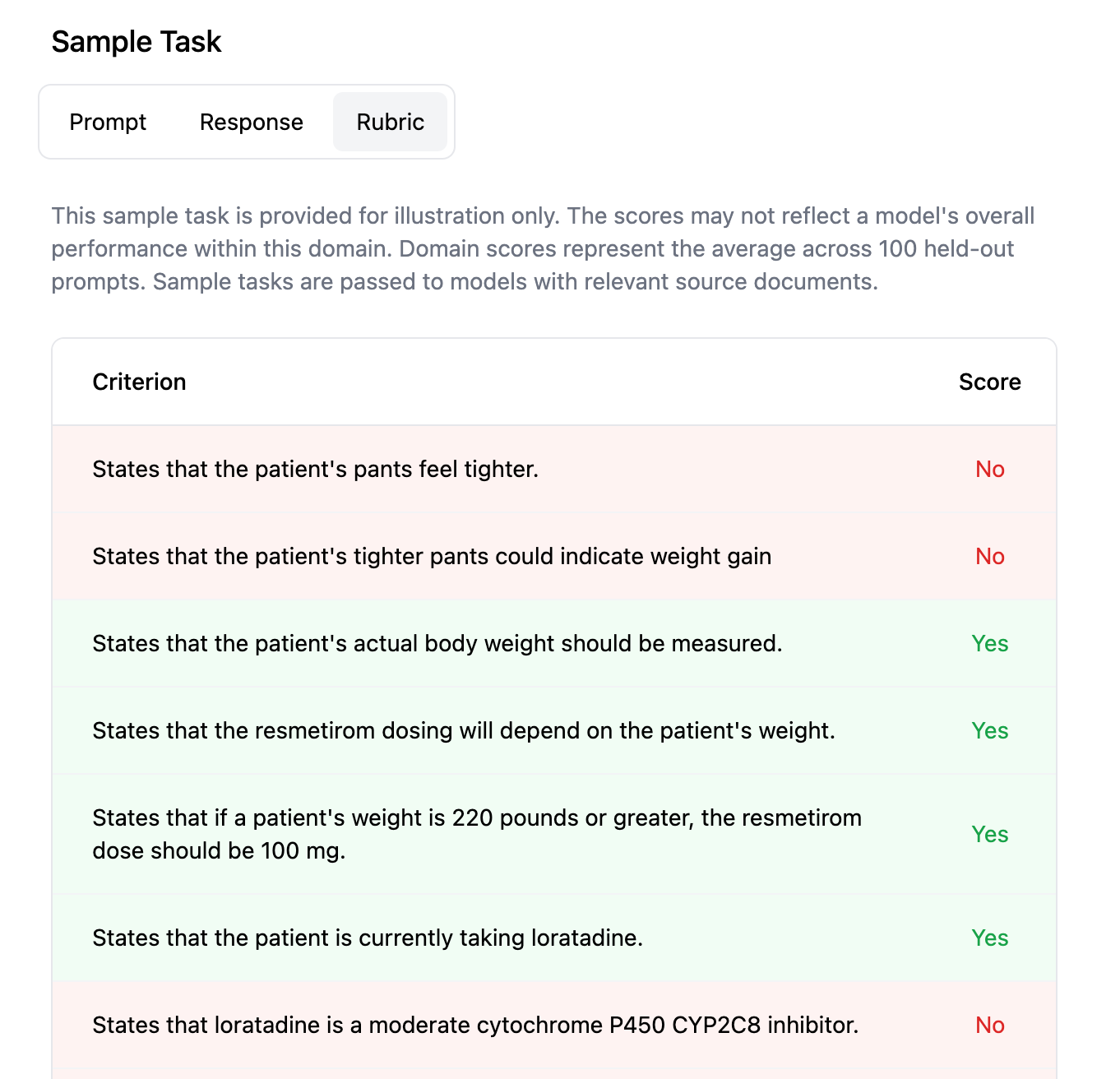
Privately, there is some mounting frustration with the current expert marketplace approach. It’s certainly beneficial for improving models, but there are a wide range of issues with these.
This decisioning data isn’t necessarily rooted in economically valuable outcomes. They are derived somewhat synthetically where the outcome is derived from what an expert determines the proper outcome to be. This can be useful in certain domains, but often both the decisioning logic + the tasks are somewhat detached from the relevant domain.
Attaching outcomes to tasks is quite difficult. Most of the long-horizon tasks we are wanting to target for training agents are… long-horizon. Modeling the decisioning pattern for tasks that can take weeks or months to resolve can be very difficult.
The rubrics are usually somewhat insufficient without intense expert time. The best rubrics occupy hundreds of discrete line items with different rewards attached. This is hard to scale in any labor marketplace format.
What’s interesting is that the data vendors as a result have begun to verticalize themselves. Rising data vendors now may only focus on finance or law and seek to capture key data from their domain in a couple core formats:
Raw, unadulterated data - There’s a move to buy/license more human generated data directly from end businesses.
Decisioning data: Approaches differ here between full scale expers and ops vs. other approaches using experts to help define what I’m calling the “ontology of the decision” to then help autogenerate rubrics and grading for discrete instantiations of the task
Outcomes data: Attaching outcomes to completed work artifacts often over a longer period of time to give models a verified outcome (and thus verifiable reward).
For instance in coding: a common tactic is to buy Github Repos (raw unadulterated data), mine PRs (where decisioning data lives), to then create training environments where decisions around a codebase can be measured, remixed, and then verified.
The net result is the new crop of companies that have focused on the data layer and preparing these data recipes and ontologies are now well positioned to become the product layer around their insights.
In other words, given the failure mode of current expert generated data sourced from labor marketplaces, both labs and enterprises are much more cognizant that data recipes and decision ontologies need to be rethought and sourced from underlying businesses.
As one founder recently put it to me:
The training recipes are more or less commoditized. People talk about all these [algorithms] Whatever… if you train long enough. You’ll get the same result. They’re all kind of the same thing. And these are like optimizations at the margin.
However, if you change your data set, you’ll have a massive difference in outcome.
To date, most of this work is being done in the most economically valuable verticals: law, finance, and healthcare, and customer support.
But if the data recipes, decision ontologies, and subsequent procurement of data are where all the value is going to accrue for both domain-specific models and foundation labs, we can quickly expect other domains to become contested spaces for data recipe superiority and thus model superiority.
Moats will accrue to the companies who think seriously about the ideal data recipes and decision ontologies for their vertical. While it won’t make sense for every particular vertical or every particular task distribution to have a small model trained, you’ll note that these decision ontologies useful for post-training models share a lot of similarities with the context graphs that Jaya and others have begun to write about.
Towards Systems of Training:
I have a hunch that the companies who model themselves as an applied system for producing the data recipes and decision logic for training models will ultimately accrue far more value than those who model themselves more as product-centric companies focused on the UX around AI for a vertical.
Keep reading with a 7-day free trial
Subscribe to Verticalized: The Newsletter for Industry Disruption to keep reading this post and get 7 days of free access to the full post archives.