
Current Product Architectures in Vertical AI
workflows, search, agents, and what's next

Good morning and happy Monday,
Today we are doing a tour through what’s working in vertical AI architectures.

Agentic Workflows Work
The vast majority of vertical AI platforms right now are modeled off of a traditional workflow with AI components primarily built in for document processing and communications.
The key idea here: leverage AI where traditional software doesn’t work. But don’t make everything agents.
Nonlinear just announced a fundraise to do exactly this in the AEC industry. And of course a substantial portion of Harvey’s product is built around AI workflows.
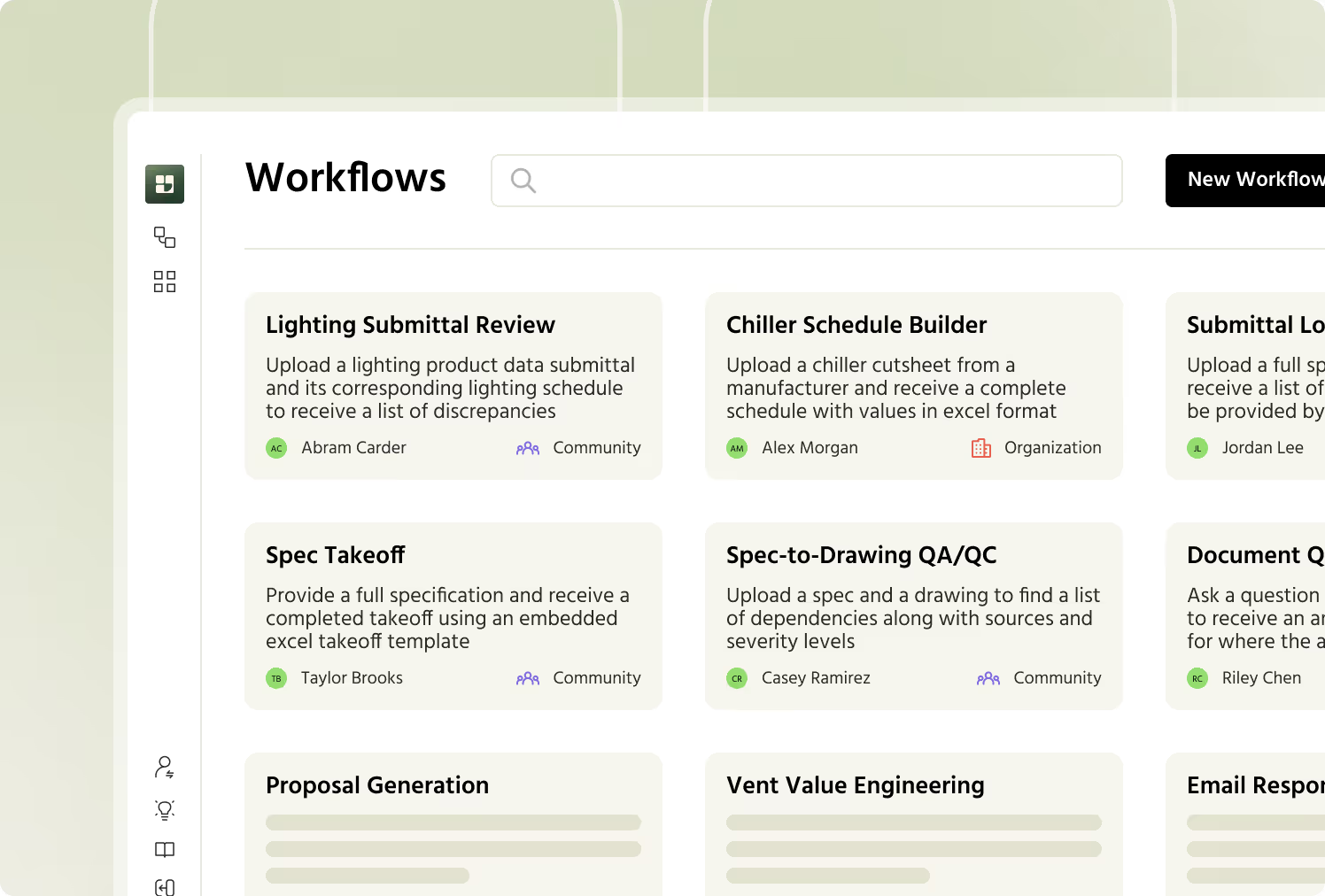
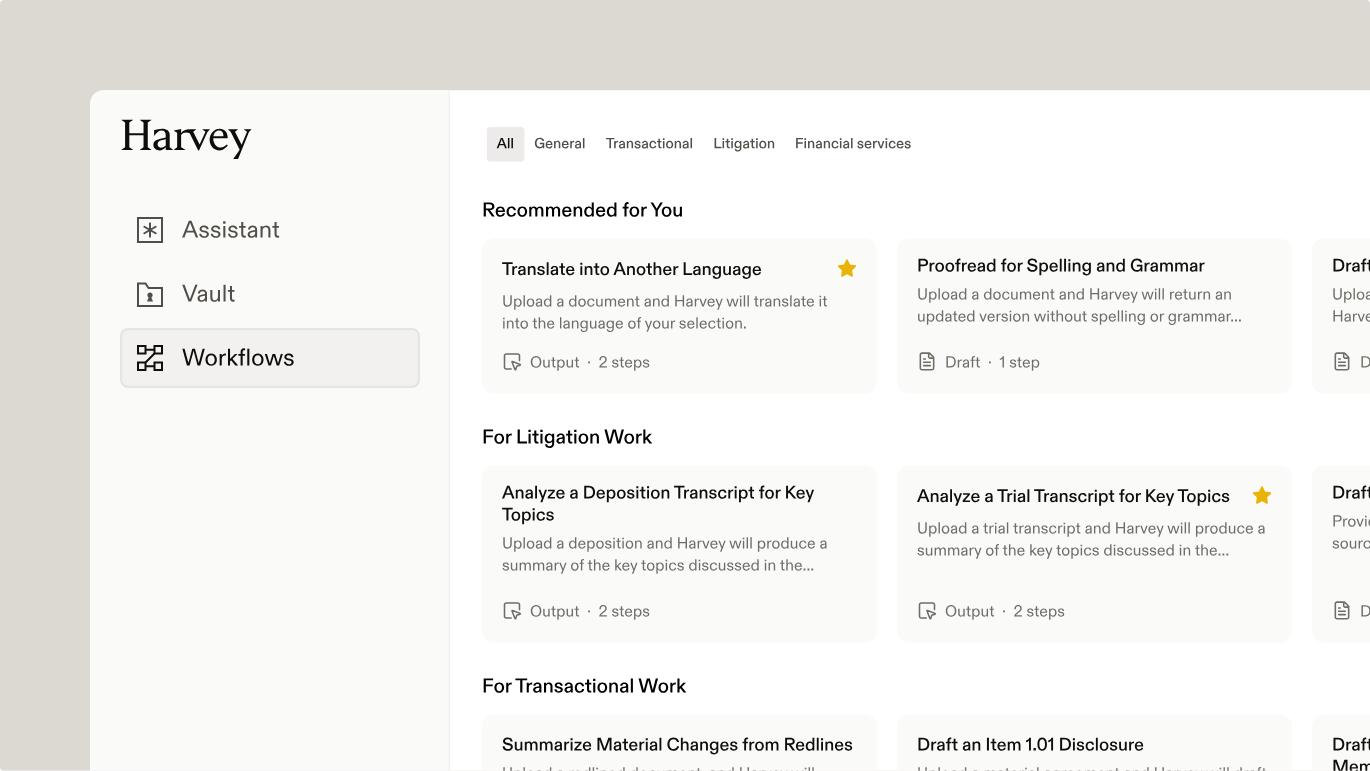
Typically, vertical AI workflows are designed to leverage the least amount of generation necessary to solve a business problem.
And nearly every fast growing vertical AI company is primarily built around AI workflows. Given OpenAI is creating SDKs to help developers create these workflows faster, it would stand to reason this is an enduring architecture going forward.
And in fact, many of these platforms may have the best claim on becoming neo-systems of record. Vertical AI workflows platforms are often going after substantial and industry-wide pain points. In turn, that naturally starts to look like accumulating a data moat.
OpenEvidence and Agentic Search
In certain verticals, professionals have to digest a breadth of information that is simply impossible.
OpenEvidence recognized this problem in healthcare and set about creating an agentic search engine across the medical corpus. The architecture here is LLMs + RAG.

The success OpenEvidence has had is somewhat breathtaking:
OpenEvidence is actively used across more than 10,000 hospitals and medical centers nationwide and by more than 40% of physicians in the United States who log in daily to make high-stakes clinical decisions at the point of care. OpenEvidence continues to grow by over 65,000 new verified U.S. clinician registrations each month. In July of 2024, OpenEvidence supported approximately 358,000 logged-in, verified U.S. physician consultations in one month. One year later, OpenEvidence now handles that many each workday—and supports over 8,500,000 clinical consultations by logged-in, verified U.S. physicians per month—a 2,000%+ year-over-year growth rate. More than 100 million Americans this year will be treated by a doctor who used OpenEvidence.1
To date, OpenEvidence has given their search product to physicians for free. Can search platforms become the basis for a system of action for physicians and hospital systems in order to reap incredible revenue payoff?
That’s starting to crystallize with their new Visits release that looks a lot like a scribing product. But the twist here is that when you have access to the full medical corpus + specific patient visit data, you can likely begin to provide a litany of extremely valuable insights for patient care. And that’s can be monetized.
Agents work(?)
Are agents working? In my view, this is the biggest architectural question for AI services over the next 10 years.
Here’s why:
Selling work and labor can not be reduced to a series of workflows. Work requires intelligence. To some degree, this is the enduring moat of many AI services companies. Through leveraging AI, they are able to create more throughput in the specialized human labor inside their business.
And so the core question: can you enable even more throughput in specialized labor via taking over more and more of the “intelligence” required for individual tasks?
A tractable example: when does an architect no longer need be generating the actual CAD and design plans in a BIM solution?
When can a game designer generate assets in their game engine with near effortless ability?
When can other domains start to experience the Claude Code moment for their work?
I’m not sure. But it’s coming. And across the agent landscape, several patterns are starting to emerge to bring this to life.
The core ideas: vertical AI agent companies are going to spend a lot of their time thinking deeply about the right mix of custom tools, libraries, and context to give their agent. Don’t reinvent the agent devops. Concentrate time and attention on the right harness for agents.
Harnessing as a Service:
I really love the idea expressed in this graphic:

The author here makes a very simple point as it applies to agents:
Don’t do devops. Use Claude Code and off the shelf SDKs
Your value comes from the “harness” you give your agent. This is the set of tools, custom prompts, context, and sub-agents you give.
Here’s the money quote:
We’re moving rapidly towards a world where builders create custom harnesses and users plug into them to edit further or use as a product. We’re already starting to see this movement from companies like bolt who helped kick off the vibe coding revolution. They’re using Codex and Claude Code in their app building product directly and probably did a ton of harness customization to get the product to work well. There’s a massive opportunity for companies to start using existing harnesses as application primitives to build their product experiences around. My bet is that in the next 6 months, the majority of user facing AI products will be using an existing agent harness as their core user interaction pattern.
I think this is directionally right and there’s widespread vertical applicability.
In short, I think the agent world is quickly moving into a space where developers spend their time creating the right tools for agents to wield in the right harness.
The structure and development of these tools is perhaps the now the greatest open question for vertical agents.
Less is More: Smaller models as tools?
Last week, a paper from Samsung came out detailing a new model that obtained fairly impressive accuracy scores on some benchmarks.
The shocker? It only had about 7m parameters. LLMs? They typically have hundreds of billions of parameters.
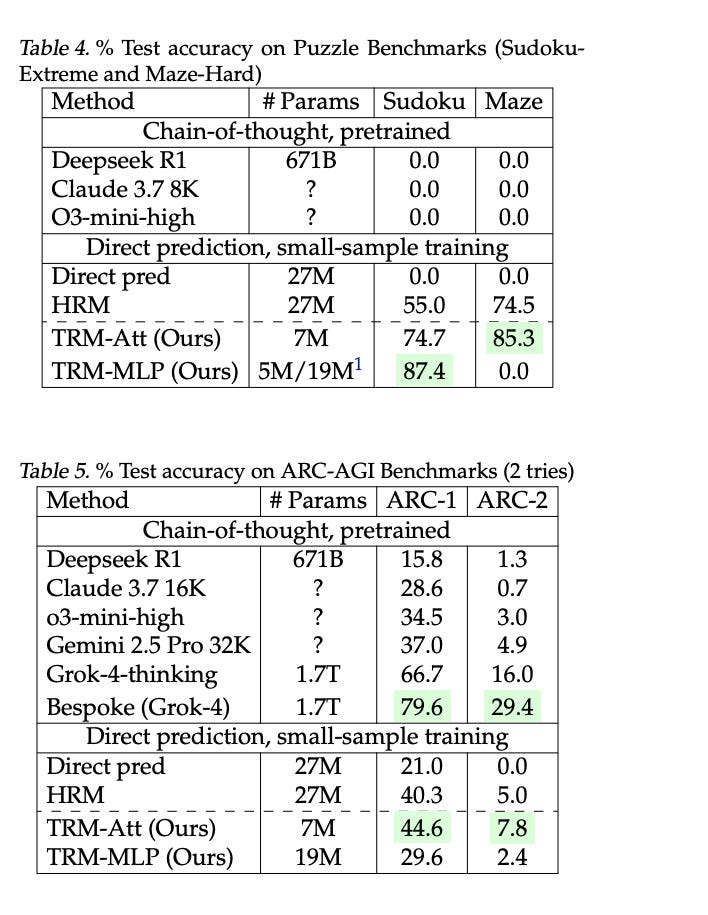
This new model, called a Tiny Recursive Model (TRM), is based off another model paradigm that came out of China a few months back.
The big idea here: for problems that require heavy logic-based reasoning, how a model thinks is far more important than its size.
I’m going to go ahead and quote from Mostly Borrowed Ideas on the comparison between LLMs and this TRM here:2
Large Language Models (LLMs) like Gemini or GPT-4 typically generate answers… one word or token at a time. When solving a complex problem, they try to produce the solution in a single forward pass. If they make an error early on, they struggle to recover, often rendering the entire answer invalid.
To compensate, LLMs use techniques like Chain-of-Thought (CoT)… and Test-Time Compute (TTC), where they generate multiple answers and select the best one. However, these methods are computationally expensive and still fail on tasks requiring deep, multi-step logic, such as complex Sudoku puzzles, maze solving, and abstract reasoning benchmarks (i.e. ARC-AGI)
TRM [instead]… operates much like a human solving a difficult puzzle: iteratively making guesses, evaluating the consequences, and revising the guesses until a solution is found...
It keeps two things in memory: y: its current best guess for the answer, and z: an internal “scratchpad” of reasoning. At each step it updates z a few times, then updates y once, and repeats. That’s it. The loop lets a 2‑layer, ~7M‑parameter network iteratively fix its own mistakes (“less is more”).
Okay, so why should you care?
Well for one, this specific training run cost less than $500. Two, the data required to gain this performance was also incredibly small. We are talking about a couple thousand input/output pairs vs. the entire corpus of the internet.3
But here’s the business reason:
Agents can make great harnesses. But state of the art is quickly pointing to a world where smaller models can be more performant on subdomains than LLMs.
Is there a future where harnesses and foundation model-based agents leverage smaller models for specific domain tasks? Almost undoubtedly so. And that opens up some new potential moats for vertical AI companies against foundation models.
AI has a last mile problem in delivering the requisite performance to wholesale change a profession and render specialist labor more effective.
But perhaps smaller models aren’t the answer. There’s some bright people that are fairly convinced that current models are sufficient for nearly every domain.
Software Libraries as Tools
What are models extremely effective at in agent contexts? Code development. And in particular code development in Python and JavaScript.
In short, every domain has a list of software libraries that allow developers to wield massive amounts of leverage over work inside the domain:
That looks like a list of traditional software that is instead built and exposed specifically for agents:
Canonical data models for the vertical
Deterministic primitives: validators, calculators, normalizers, parsers, scorers, matchers for work product in the domain.
Regulatory and policy logic embedded as code (eligibility rules, compliance checks, audit trails).
Integrations to systems of record
Safety rails: permission checks, PII/PHI tagging, redaction, and guard policies that the agent cannot bypass.
In theory, the goal here is rather than have an LLM live inside a workflow, turn many of the safeguards built into the workflow into software libraries and harnesses that agents are built to use natively.
These domain packages can start basic (an insurance policy parser) and quickly grow into potentially fully featured environments for both agents and humans to collaborate in (a new, agent-native BIM solution).
But whether through new software library packages developed entirely for agents to be able to wield effectively or through smaller models used as a tool for tasks, it seems clear that there are tractable paths forming for widespread agent adoption in myriad industries.
The future of vertical AI may very well belong to those who build the libraries that make intelligence usable.
https://www.prnewswire.com/news-releases/openevidence-the-fastest-growing-application-for-physicians-in-history-announces-210-million-round-at-3-5-billion-valuation-302505806.html
https://www.mbi-deepdives.com/less-is-more/
Note: The TRM approach is promising but still not language-based. This is one to follow because of what it represents in complex domains (construction, architecture, manufacturing, oil and gas, and more, but still is nascent)