
What's Coming in 2026?
The Age of Dichotomies bleeds into the Age of Deployment

Good morning,
Today, an overview of 2025 and where I think we are headed in 2026.

My 2025 Chain of Thought: The Age of Dichotomies
Model Progress
Vibes around current gen models are all over the place. Some point to Opus 4.5 being AGI, users on LMArena report that GPT 5.2 is worse than most model releases from the year.1
Ilya reports that the Age of Scaling is over and we are in a new Age of Research. At the same time, scaling models for economically valuable tasks is still in the early innings. The abbreviated lesson of 2025 is that if a) we can obtain reasoning data and b) accompanying evaluations for models that can c) act in economically valuable environments, we can hillclimb both large models and small models on these tasks and capabilities.
What’s the actual number of occupations and economically valuable work that we have catalogued with sufficient nuance for training? My back of the napkin math is that we have probably catalogued with sufficient rigor less than 2% of the labor force and likely less than 5% of contributing GDP?
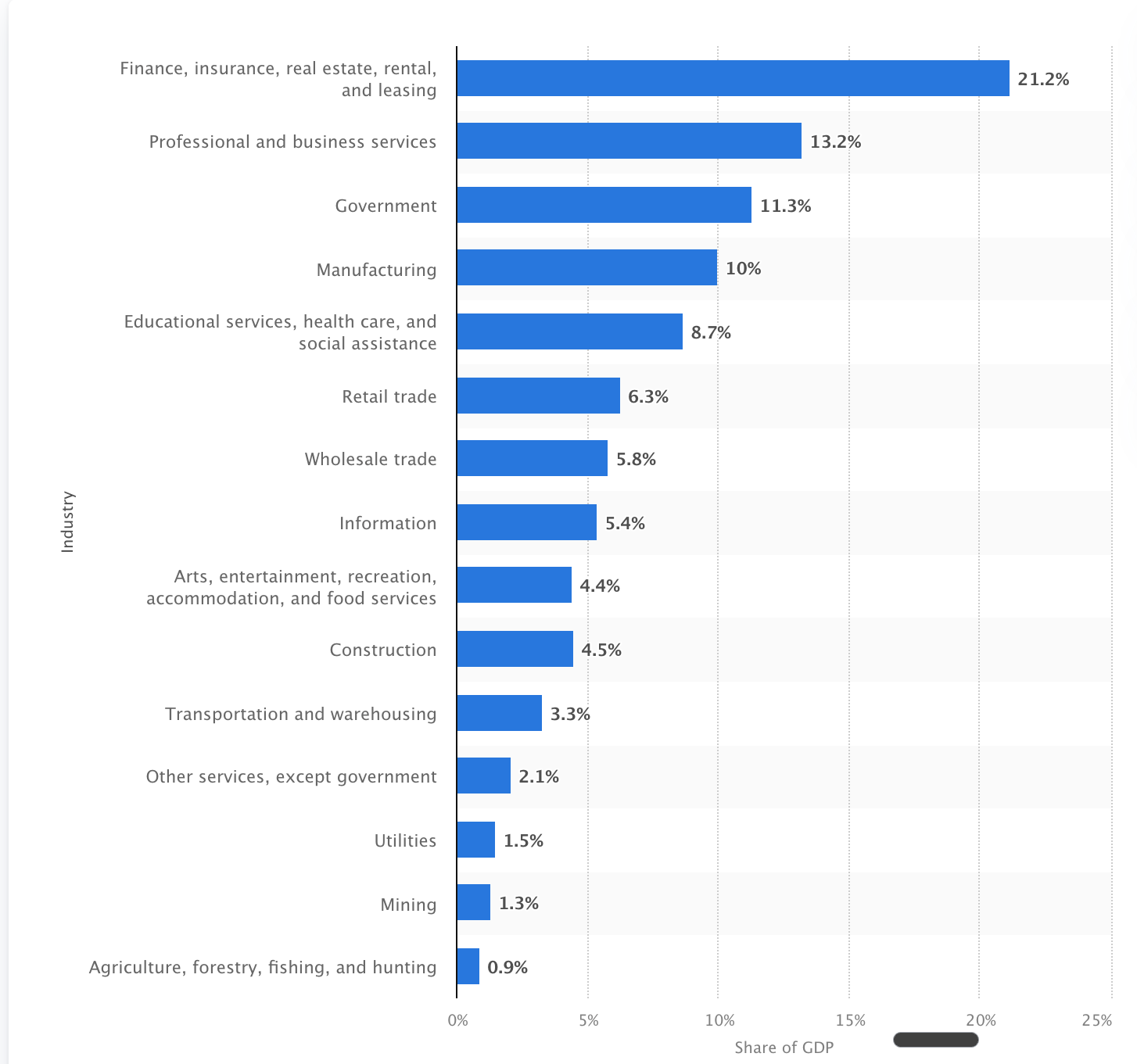
With current model architectures and training techniques, it’s somewhat rational to believe that we can hillclimb nearly every occupation at least into a heavily AI-assisted occupation with current technology. If we use software engineering as emblematic of what’s possible, we would be looking at expected productivity gains of 50-70% across the entire economy even without continual learning. If some new architecture paradigm cracks problems like continual learning? We are now talking about wholesale replacement.
From this perspective, the last remaining challenge in AI’s proliferation in the economy is getting useful training data. At the end of the day, it’s simply a data acquisition problem.
But how long does that take? It has taken us 9-12 months to get models to perform well on a narrow slice of healthcare, finance, and legal problems. Will the data acquisition rate and learning curves be exponential? Or is this a far more difficult problem than scaling compute?
Markets
In the midst of all of this, we have a venture market that is now potentially frothier than 2021, with most valuations being only rational if you believe we are in the strike zone of imminent wholesale labor automation or if vertical monopolies form.
I take it as somewhat granted that if you can wholly automate a profession or task capability, you can charge close to the average rate of labor for that automation. If you can only assist the labor, you can charge near the going rate of inference. Therein lies the dilemma for companies who even if they are 80% margin businesses still are a ways off from valuations that imply the wholesale automation of labor. You can only ride RAG techniques and base model capabilities so far.
Anecdotally, while everyone chases the explosive growth of Harvey, Abridge, and OpenEvidence, there’s been somewhat less exponential growth in many vertical AI solutions vs. 2024. There are plenty of vendors who are now hovering around the $20-30m mark but are bottlenecked by the sort of foundation model progress or smaller model progress on their end that would lead to far better value capture.
Public markets continue to bifurcate between AI tailwinds and everything else. Many investors are now publicly talking about the continued endurance of systems of record and yet growth in public software looks stalled at around 15%.
Rollups continue, but attention is now shifting to bigger targets. Some huge takeouts are beginning to be talked about. EA may be the canary in the coal mine for what’s to come in 2026. Behind the scenes, there’s growing acceptance that AI workflows with current gen models are insufficient for getting to the Rule of 60, and yet increasing confidence that RL techniques can actually achieve fundamentally better cost structures in these businesses.
Feeling the AGI
Current model sentiment is heavily indexed against coding. Claude Code has mostly solved bespoke application development. One of my friends owns an SMB with nearly no automation much less frontier AI tech in the business. Within two afternoons of Claude Code + doing some systems design, I think we have pretty much transformed his business going into 2026 and I’m fairly bullish on growing it close to 3x next year as an AI-enabled service.
It’s legitimately breathtaking what’s possible with current gen models. And yet, 98% of occupations remain entirely inaccessible to models from a capability perspective. 95%+ of GDP is untouched.
And so in my view, 2025 looked like an Age of Dichotomies stemming from the jaggedness of the data (to use Leandro’s turn of phrase) and the amount of human intervention required in agentic workflows. As good as models are, they’re still immensely dependent on humans as shepherds. In my view, 2026 will be marked as the Age of Deployment in the pursuit of smoothing out the jagged AI experience across the economy.
So some predictions. Let’s hope I’m in the right error bars.
2026 Predictions:
Video Gen x World Models ripen for production and serve as the next critical product wedge.


Video gen currently reminds me a ton of image generation in 2023 where it needed to get about 30% better to be truly transformative.
My baseline expectation is that is about to happen for video generation and once it does, it unlocks similar opportunties in GTM that voice AI did for a number of service industries. World models feel more nascnet, but then again within the past month, we are now able to build pretty accurate sims and new worlds.
If they get 70% better, a whole new host of applications for physical world companies get unlocked instantly.
One example with better world models?
Walkable floor plans but within a VR world model of the home.2
I’m fully expecting video generation to be the 2026 rendition of voice agents. Everyone crowds in with vertical applications and a whole host of industries begin to change.
Systems of Record have new life
The endurance of systems of record has been remarkable. More and more they look like true winners from AI as opposed to losers.
That said, there’s still remarkable few AI products being built by vertical systems of record. There’s the occasional chat interface or RAG search, but this has been limited.
I expect that to change over the next year as systems start to meaningfully consider the data they’re sitting on, smaller model training becomes feasible, and shipped products like Shopify’s SimGym become emblematic of what’s possible.
Small models proliferate
Swe-grep, Applied Compute, the recent acquisition of Parsed, EvenUp’s PiAI all point to a world where vertical applications and enterprises begin to build smaller task-specific models for work they care about. Distillation techniques, infra like Tinker from Thinking Machines, open source libraries like Prime Intellect, all point to a different cost profile for building proprietary models. Many of these models will have durable moats for a number of years. Building a muscle around novel model training will be a prerequisite for existing systems of record looking for an uplift in their valuation.
Terminal UI design starts to bleed into knowledge work.
Paul, CEO of BrowserBase, has a fantastic example of a terminal UI he put together here.
If you want to simplify this: I think the personal compute environments for knowledge workers get more personalized.
The terminal with Claude Code and Skills is so useful that whomever can achieve the functionality of giving knowledge workers personal compute experience tied to the terminal probably ends up with some of the most novel training data there is. Models think in file systems, API calls, context, etc. UI is going to start to match that realization for knowledge work.
I can imagine different forms of this business: everything from boutiques that are centered around customizing personal compute environments for professions to potentially Lovable style opportunities that focus on helping knowledge workers build their ideal personal compute environment.
Training data spend goes to 15B a year
The big lesson of 2025 was to simply bring out of distribution data into distribution. This will becomes an even bigger emphasis for labs and researchers. The industrialization of training data will ensure.3
Evals for Economically Useful Work Proliferate
Rubrics, reasoning problems, in-domain tools and workflows, all end up becoming points of emphasis for labs and application companies. Vertical AI companies will begin to publicly put out benchmarks as they become more research-centric organizations as they too realize that revenue is directly tied to the task capabilities of their models.
I’m also frankly predicting this because it’s something I’m actively working on and we are partnering with some fun companies to do. Reach out if you’re interested.
Somebody builds a gaming support studio as an AI-enabled service
Gaming studios have been bottlenecked on adopting AI because of revolt inside their developer core. The natural play will be for execs to outsource even more tasks to support studios leveraging AI for QA, design, console migrations, voice work, etc to give air cover but get productivity gains.
Support studios take no IP risk and so a business here could fully focus on AI transforming the unit economics of the services. I think this is one of the best opportunities out there if you have the right connections into gaming studios and I fully expect someone to give it a go.
Compute Markets get Weirder:
Smaller models proliferate, spot markets, and derivatives are now out in the wild and fully utilized, and every significant AI team starts building out hedging arms. By end of 2026, at least one significant trading desk is indicating that they are building out a compute desk.
Overall
In my view, the Age of Deployment beats the Age of Research as a descriptor because deployment is one of the only scalable ways to obtain the data necessary for continued model improvement. Much of the economy is still not instrumented for models. So 2026 overall will look less like a single intelligence explosion and more like a long, uneven rollout as teams continue to deploy but with more of an eye towards advancing model capabilities through their deployments vs. commercializing some latent ability models already have.
At the same time, 2026 will also see the rise of AI veganism. Model progress has coincided with tech exhaustion amongst the general populace. Life is more expensive, the American Dream feels more contested, and junior jobs are becoming automated. All of that will lead to a growing set of opportunities in the physical world that has nothing to do with AI. And I think it’s probably best that these opportunities remain illegible. After all, if they’re on the internet, the models will soon know about them. For now, they should remain secrets.
LMArena is a terrible true evaluation tool and a great vibe tracker for the median AI user.
Example of this business here: https://www.walkableplans.com/